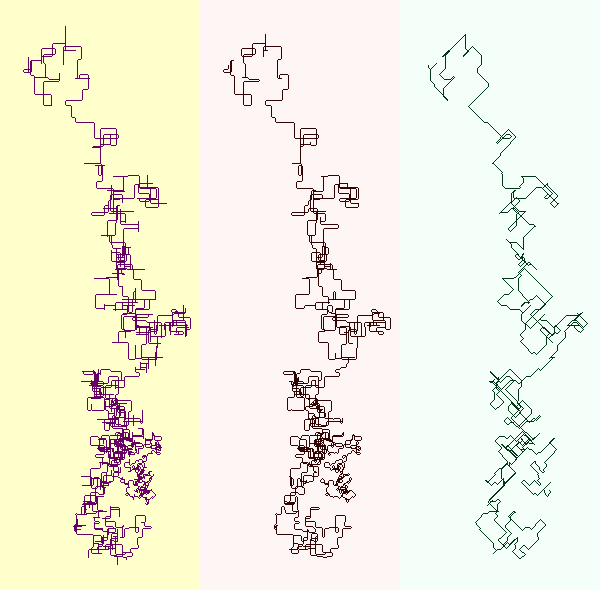I think the problem statement was intentionally difficult to parse this time. Those conditionals are a lot simpler than it makes them sound.
I kept the visited positions in a Hashed_Set and coming up with a good Hash function for a pair of Integers was new for me. I ended up making a lot of assumptions (Integer'Size = 32 and Hash_Type'Size = 64) and just shifted one of the integers left 32 bits. A cursory Google search turned up the Cantor Pairing function, but I wasn’t able to make this work with negative integers in a short amount of time. Clearly I need to do more reading.
Part 2 caught me off guard, I hadn’t anticipated I’d need to deal with more elements.
Note: I’m going to stop using the spoiler blur on the daily posts. If you’ve gotten this far, I assume you know that these posts contain spoilers.
This is another case where a program that solved the examples solved the puzzle.
My solution is similar to @JeremyGrosser’s, except that…
I’m also not that familiar with coming up with a hash function; I seem to remember that multiplying by relatively large primes is a good idea, and of course I didn’t do that my first time through, so after reading his comment here I went back and changed how I was doing things.
I had a different approach to the case where one might have to move diagonally. I’ll have to go back and check whether I can simplify what I did, but I like @JeremyGrosser 's Adjacent function .
While I didn’t this, you could avoid hashing negative numbers by starting at a position far above and to the right of the origin. A scan of the input file should give more than enough buffer for this.
I couldn’t be bothered to write a hash so I wrote a lexicographic ordering function and used Ordered_Set instead. I spent some time trying to figure out how to move the tail, but I think I ended up with a very elegant solution using some vector math and integer division.
Used an ordered set, too, but using 2-element arrays as data type instead of records, skipping the need to define the ordering myself. Once again, it was nice to see that solving part 2 required no change of the core logic.
It seems my assumption about the size of Hash_Type was wrong, it’s only 32 bits wide. However, this means I can Unchecked_Conversion (Integer, Hash_Type). Shifting 16 bits from there and using xor gets us a pretty good hash function for small values of Integer, which is the common case for this problem.
type Position is record
Y, X : Integer;
end record;
function Hash (Element : Position)
return Ada.Containers.Hash_Type
is
use Ada.Containers;
function To_Hash_Type is new Ada.Unchecked_Conversion
(Integer, Hash_Type);
begin
return (To_Hash_Type (Element.X) * 2 ** 16) xor To_Hash_Type (Element.Y);
end Hash;
On my Part 1 solution, this hash function drastically improves L1 cache efficiency and results in a 12.3x speedup!
It’s the first time I use Functional_Maps container. I used Hashed_Maps in the past, and today I discovered this functional version. I noticed three main differences. In Hashed_Maps: you must specify the hash function, the API is based on procedures with in out parameters and SPARK_Mode is off. In Functional_Maps: you’re not required to provide the hash function, the API is based on functions that return a new map whenever you modify it (add, remove, set) and SPARK_Mode is on.
I don’t know what are the internal differences between them regarding memory requirements and performance. A comparison of both APIs would be also interesting. For today’s puzzle, both containers are good enough, but I think that the functional flavor makes the code more readable.
With respect to SPARK, it exists also the Formal_Hashed_Maps container with SPARK_Mode which (I suppose) it has been formally verified. I’m not sure if it’s the same for Functional_Maps, because is based on Functional_Base that has no SPARK support.
A banana skin I slipped over for part 2 is that there are multiple solutions to the problem.
In the first variant I have applied the rule, for each head-tail pair (be it on part 1’s length 1 rope, or part 2’s length 9 rope): when the new head position is not touching the tail, the tail moves to the former head position.
After my answer was not accepted, I have considered having a glimpse to the the AoC forum.
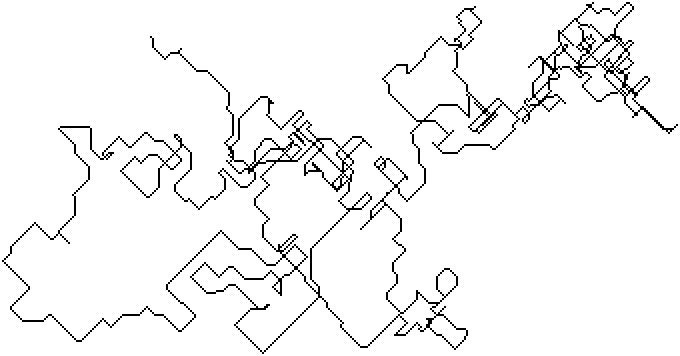
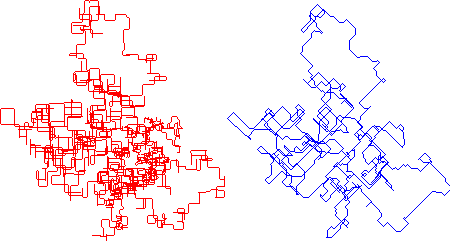
Below you see the path of part 1’s tail for my input, then the “wrong” solution for part 2 in the middle and the “right” one on the right.
L1 is kinda hard to instrument, but the perf stat command will give you some info on cache activity. If there’s little or no L2 activity, then you can infer that the data is mostly in L1.